
Réplication, Reproductibilité, Réutilisation : concepts et enjeux
#ZOOM SUR…
Professeure en informatique à l’université Paris-Saclay, membre du Laboratoire interdisciplinaire des sciences du numérique (LISN, UMR9015, CNRS / Université Paris-Saclay), Sarah Cohen-Boulakia est directrice du groupement de recherche Masses de Données, informations et connaissances en sciences (MaDICS, GDR3708, CNRS). Spécialiste en science des données des questions liées à l'analyse et à l'intégration de données biologiques et biomédicales, elle a notamment publié des articles dans le domaine de la reproductibilité des analyses bioinformatiques et a été, depuis 2020, impliquée dans la gestion de données COVID. Elle est très investie dans l'enseignement de l'informatique à des publics divers, notamment issus de la biologie.
Nous avons toutes et tous rencontré un jour une difficulté à retrouver un résultat que nous avions pourtant nous-même établi ou une impossibilité à reconstruire un résultat obtenu par un pair. Cette difficulté ne doit pas être minimisée car la capacité à reproduire un résultat est un des fondements de la démarche scientifique, de la science dite cumulative où les résultats se fondent sur ceux qui les précèdent. Le scientifique peut être vu comme « travaillant sur les épaules d’un géant », et le manque de reproductibilité peut être assimilé à la fragilité du « colosse aux pieds d’argile », affaibli par des fondations qui manquent de robustesse.
La reproductibilité est communément définie comme la capacité à produire à nouveau (reproduire) un résultat existant. Assurer la reproductibilité d’un résultat c’est fournir le maximum d’information sur la façon dont il a été produit : le protocole suivi pour le produire, les objets dont il dépend (échantillons, données, logiciels, conditions expérimentales...).
La problématique de reproductibilité existe dans de nombreux domaines. Sont présentés ici les enjeux associés à trois types de reproductibilité1 communément cités.
Assurer la reproductibilité empirique d’un résultat — par exemple la présence d’un précipité en chimie — c’est garder la trace des conditions dans lesquelles l’expérience a eu lieu (le PH, la température…), des ingrédients qui ont composé cette expérience (les espèces chimiques impliquées) et du protocole suivi pour la réaliser (ordre des étapes, matériel utilisé…). La reproductibilité empirique est souvent difficile à atteindre parce que certaines expériences requièrent une précision importante dans la reproduction des conditions expérimentales (dosage exact des composants…).
Assurer la reproductibilité statistique d’un résultat c’est garder la trace de la raison qui fait qu’un résultat est significatif au sens statistique : la justification du choix du test statistique, des paramètres du modèle statistique, des valeurs de seuil, de la taille des échantillons… La reproductibilité statistique, lorsqu’elle n’est pas atteinte, est souvent liée à une erreur scientifique : on a cherché à reproduire un résultat dans un contexte statistique différent du contexte initial — le jeu de données n’a pas les mêmes caractéristiques (plus grand, plus petit, biaisé…).
Assurer la reproductibilité computationnelle, c’est garder la trace de la façon dont a été produit un résultat via une machine : les codes informatiques utilisés, leur enchainement, leur version mais aussi l’environnement logiciel sur lequel les codes ont été exécutés — le type de machine, les logiciels qui y étaient installés — et enfin les jeux de données utilisés.
Face aux reproductibilités empirique et statistique, la reproductibilité computationnelle semble la plus facile à contrôler : elle ne dépend pas de conditions naturelles, elle ne semble pas requérir d’expertise disciplinaire forte. Cependant, la crise de la reproductibilité a éclaté au début des années 2000 et a mis en lumière des erreurs fréquemment présentes dans de très nombreuses disciplines. Contre toute attente, le numérique est à l’origine de nombreux cas de non-reproductibilité.
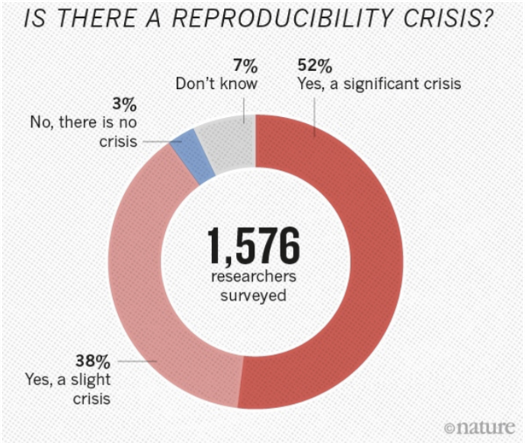
Image empruntée à : Baker M. 2016, 1,500 scientists lift the lid on reproducibility, Nature 533:452–454
Il est ici nécessaire de mieux définir les concepts sous-jacents à la reproductibilité en définissant différents niveaux de reproductibilité2 : du plus précis au plus générique.
Le premier niveau de reproductibilité est celui de la répétition, c’est-à-dire de la reconstruction à l’identique. On applique à nouveau, et le plus fidèlement possible, le protocole, dans les mêmes conditions, avec les mêmes codes, et les mêmes données. Ici, l’enjeu est de figer le résultat, et donc d’être capable de décrire les conditions exactes dans lesquelles il est obtenu. Ce premier niveau est fastidieux et difficile à atteindre car il requiert une longue documentation. Mais il est fondamental car il décrit un contexte précis dans lequel le résultat est valable.
Le second niveau est celui de la réplication : on autorise certains paramètres à changer leurs valeurs et on observe les variations de résultats. C’est le niveau où l’on comprend mieux le résultat scientifique : on isole les conditions qui déterminent le résultat, et on identifie les paramètres dont la variation n’influe pas sur le résultat scientifique.
Le troisième niveau s’abstrait de la méthode, peu importe qu’un appareil ou un autre ait été utilisé, qu’un algorithme ou un autre ait été utilisé — le résultat peut s’obtenir de différentes façons. Le fait que la terre soit ronde peut se prouver en naviguant à travers les océans, en observant des éclipses de Lune. On appelle souvent ce niveau la reproductibilité.

Pourquoi la crise de la reproductibilité a-t-elle lieu ?
D’abord et avant tout, cette crise a été accélérée par le rythme auquel on a assez subitement demandé aux scientifiques de publier, le publish or perish. Obtenir un résultat reproductible prend du temps, il nécessite de nombreuses vérifications, implique plusieurs collègues de profils différents.
La deuxième raison concerne le manque de moyens de support à la recherche. L’utilisation croissante de nouvelles technologies et l’accès grandissant à de nombreux outils numériques et statistiques ne peuvent se faire sans personnes supports, techniciens et ingénieurs dont le rôle est d’aider à garantir la reproductibilité.
Le troisième point est le manque de reconnaissance offerte à celles et ceux qui font l’effort de produire des résultats reproductibles et réutilisables.
Le quatrième point touche au manque de formation aux enjeux de la reproductibilité tant au niveau des personnels déjà en poste que des jeunes futurs scientifiques. Sur ce plan, plusieurs initiatives existent comme le développement de « ReproHackathons », enseignements dans lesquels on apprend aux étudiants diverses techniques pour reproduire le résultat d’une publication, et savoir questionner ce résultat. Le groupement de recherche Masses de Données, informations et connaissances en sciences (MaDICS, GDR3708, CNRS) a eu, dès 2015, une action sur la thématique de la reproductibilité et a organisé une série de « ReproHackathons ». Ces hackathons sont aujourd’hui à la base d’un cours de Master à l’Université Paris-Saclay3 . D’autres initiatives invitent à l’échange comme les ReproducibiliTea, Journal Club et séminaires présents dans une partie importante en Europe et en Amérique.
Plus généralement, des réseaux nationaux de reproductibilité se montent un peu partout dans le monde, formant un réseau international. Le réseau français est en cours de création, il regroupe un nombre croissant de chercheurs, enseignants-chercheurs et ingénieurs. La prochaine rencontre du réseau aura lieu à Grenoble du 26 au 28 mars 2024, nous espérons y être encore plus nombreux qu’à la première édition en 2023 qui a déjà rassemblé plus de 150 participants !

- 1Stodden V., Leisch F., Peng R. D. (Eds.) 2014, Implementing reproducible research, CRC Press.
- 2Cohen-Boulakia S. & al. 2017, Scientific workflows for computational reproducibility in the life sciences: Status, challenges and opportunities, Future Generation Computer Systems, 75: 284-298.
- 3Cokelaer T. & al. 2023, Reprohackathons: promoting reproducibility in bioinformatics through training, Bioinformatics, Volume 39, Issue Supplement_1, June 2023, Pages i11–i20. https://doi.org/10.1093/bioinformatics/btad227
Contact