Un nouveau catalogue pour l’accès aux données quantitatives en SHS
#OUTILS DE LA RECHERCHE
L’accès aux données en France est encadré par deux textes majeurs. Le premier est le règlement général sur la protection des données (RGPD — règlement UE 2016/679 du Parlement européen et du Conseil du 27 avril 2016), qui encadre le traitement des données pour protéger les citoyens sur l’ensemble du territoire de l’Union européenne. Le second est la loi française « pour une république numérique » (loi n° 2016-1321 du 7 octobre 2016) qui travaille à ouvrir les données tout en renforçant la protection des personnes.
Le premier vise à protéger les citoyens et restreint, en conséquence, l’accès aux données les concernant. Le second vise à ouvrir les données existantes pour qu’elles puissent servir au plus grand nombre. Ces deux textes ont donc pour ambition que les données soient, selon la formule maintenant classique, « aussi ouvertes que possible, aussi fermées que nécessaire ». On distingue alors deux grands types de données : les données anonymes, qui doivent être ouvertes et accessibles au plus grand nombre, et les données confidentielles, dont l’accès doit être soumis à des autorisations spécifiques.
Le site gouvernemental https://data.gouv.fr donne accès aux données ouvertes, et est désormais complété par un site spécifiquement dédié aux données de recherche. Le comité du secret statistique autorise l’accès aux données confidentielles sous la forme de fichiers détaillés ou pseudonymisés. Les données confidentielles détaillées sont accessibles via le centre d’accès sécurisé aux données. Les fichiers pseudonymisés (aussi appelés « Fichiers Production Recherche » ou FPR) sont, quant à eux, accessibles via le dispositif « Quetelet-Progedo-Diffusion ».
Quetelet-Progedo-Diffusion
À l’initiative du Laboratoire d’Analyse Secondaire et de Méthodes Appliquées à la Sociologie (LASMAS), et dans la continuité des préconisations du rapport sur « les sciences sociales et leurs données »
La « fairisation » des données
Cette documentation des données, c’est-à-dire la création de métadonnées associées aux jeux de données, répond au besoin de comprendre comment elles ont été construites et comment elles seront utilisables ensuite. Si la documentation et les données ne sont pas accessibles, cela n’a pas de sens. C’est dans cette perspective que Wilkinson et al.
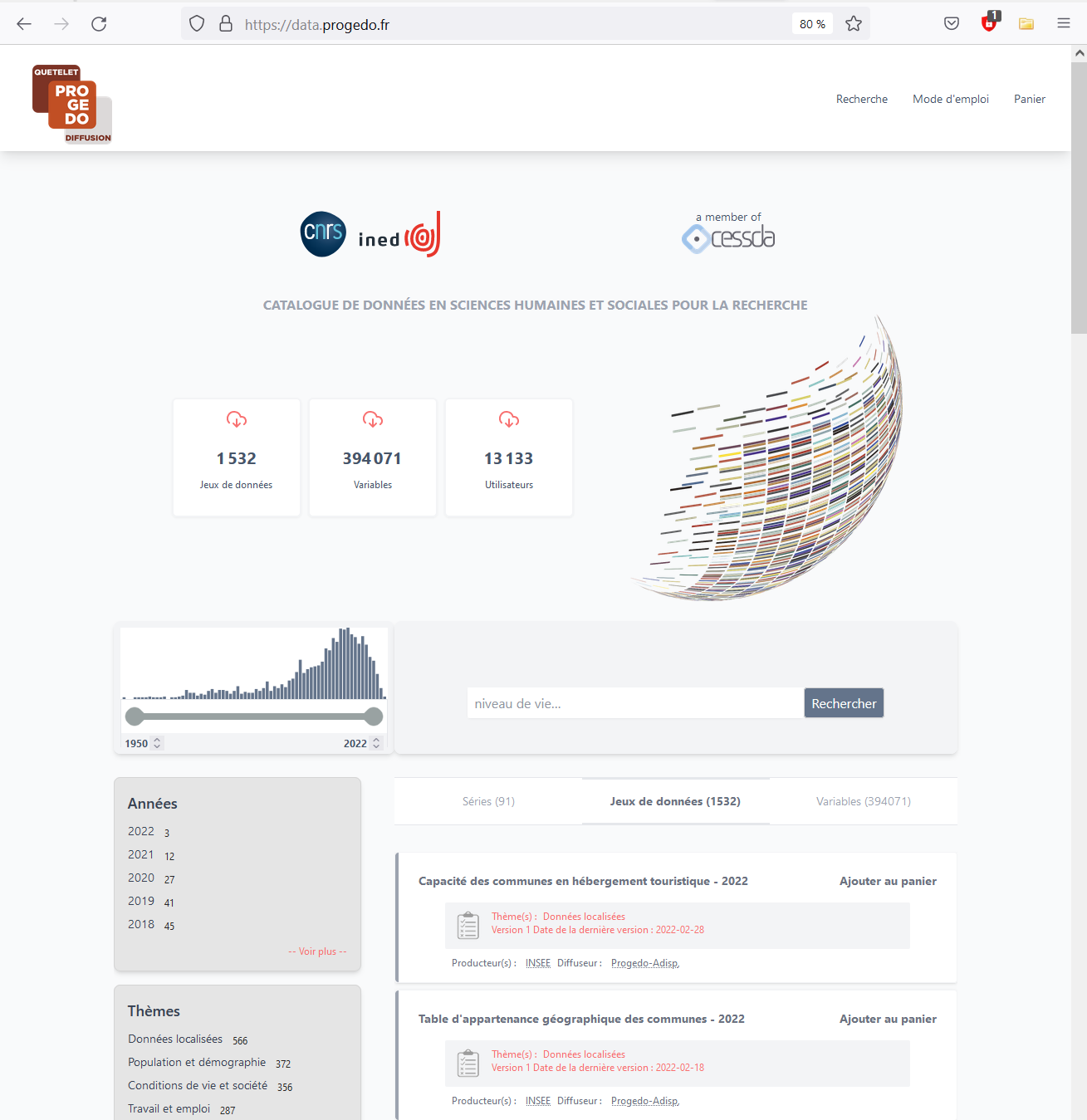
En termes plus concrets, cela se traduit par un bon catalogage qui permettra de les trouver, et la disponibilité en ligne de ce catalogue. Celui de Quetelet-Progedo-Diffusion est hébergé sur les serveurs mis à disposition et entretenus par l’IR* Huma-Num, ce qui lui assure une grande disponibilité technique. Il est en outre moissonné par les moteurs de recherche conventionnels (Google, Bing, etc.) et par des moteurs spécialisés comme Isidore. Il repose sur une documentation construite selon le standard de la Documentation Data Initiative, communément appelée DDI, et propose depuis cette année des identifiants uniques et pérennes (les DOI fournit par l’Inist du CNRS).
Un enjeu essentiel : accéder à la documentation des données et des variables
L’utilisation de la norme DDI permet de documenter de manière très fine les enquêtes et les bases de données en sciences humaines et sociales. On distingue habituellement une « partie haute » de la documentation, qui décrit l’enquête ou la base de données (de manière non exhaustive : résumé, thème, mots-clefs, producteurs, date, mais aussi temporalité, échantillonnage, conditions de la collecte, traitements des données, etc.) et d’une « partie basse » qui présente les variables (texte de la question, type de la variable, nombre de réponses, modalités, etc.).
Ce sont ces éléments qui vont permettre aux chercheurs et chercheuses de trouver les données qui correspondent à leur questionnement. Un moteur de recherche performant est donc nécessaire pour proposer des réponses pertinentes émanant aussi bien des parties hautes que des parties basses.
Un nouveau du catalogue pour Quetelet-Progedo-Diffusion
Le catalogue et l’outil de commande de Quetelet-Progedo-Diffusion dataient d’une dizaine d’années et étaient devenus obsolètes. Par ailleurs, le catalogue ne proposait pas de moteur de recherche et il fallait passer par un outil spécifique pour la partie haute et par un autre pour la partie basse, les modalités des variables étant, quant à elle, proposées sur un troisième site… L’IR* Progedo, soutenue par le Ministère de l’Enseignement supérieur et de la recherche, a donc décidé de développer un nouveau catalogue en open source. Le développement a été assuré par l’équipe de DBnomics
Aujourd’hui, ce nouveau catalogue est en ligne et répond aux promesses. À travers une interface ergonomique, les chercheurs et chercheuses peuvent interroger l’ensemble des 1 500 jeux de données (dont 97 séries temporelles) et 380 000 variables. Les résultats de la recherche s’affichent « à la volée » pour les séries, les jeux de données et les variables. Chaque jeu de données est désormais doté d’un identifiant unique DOI, ce qui permet de les gérer en utilisant des logiciels comme EndNote ou Zotero et donc de faciliter la citation des données dans les articles.
Enfin, ce catalogue est désormais accessible via le métacatalogue du Consortium européen des archives de données en Sciences Sociales (CESSDA) et participe donc à l’European Open Science Cloud (EOSC).
Le développement de ce nouveau catalogue était nécessaire et a permis de nombreuses améliorations qui doivent faciliter la vie des chercheurs et chercheuses. La collaboration établie avec DBnomics va permettre de continuer d’améliorer cet outil dans les années à venir, la prochaine étape étant d’y intégrer l’outil de commande des données.